За последние шесть лет я прошёл через дюжину проектов, связанных с поиском. Роднило их немногое, кроме того, что практически в каждом я обнаруживал одни и те же ошибки. Не сговариваясь, разные команды спотыкались в одних и тех же местах. Эта статья — каталог самых живучих ошибок при проектировании поиска, кочующих из проекта в проект. Примеры построены на ElasticSearch, но большинство пунктов применимы к любому поисковому стеку.
Статья будет полезна как тем, кто еще не делал поисковых систем и столкнулся с проблемой “чистого листа”, так и тем, кто уже имеет какой-то поиск и нутром чует неладное, но не может понять, что не так.
А чтобы было интереснее и веселее, разбирать ошибки мы будем в формате вредных советов, следование которым гарантированно испортит UX ваших пользователей и сделает поиск по вашему ресурсу бесполезным, ненадежным и ужасно дорогим. Поехали!
Почему все так плохо?
Перед тем как начать говорить о конкретных проблемах, хочется понять, почему вообще так получается. Ведь в сети есть огромное количество материалов, как делать поиск, есть устоявшийся набор инструментов, есть удачные проекты, которые показывают “как надо делать”.
Основная проблема доступных материалов в том, что они очень схематичны. Большинство из них затрагивают общие вопросы и дают на них такие же общие ответы. Книга по проектированию и разработке прикладных поисковых систем в веб-проектах (если бы ее кто-нибудь написал), могла бы выглядеть так:

Собственно далеко за примерами ходить не надо: моя прошлая статья описывает очень верхнеуровневые вопросы. Этот материал нельзя взять и построить на его основе систему, избежав типовых проблем.
Да, нам в помощь есть документация по конкретным решениям, которые используются в поисковых приложениях, но они зачастую фокусируются на технических деталях, редко и неохотно описывая общие концепты, которые помогут спроектировать поиск хорошо. Самые интересные темы в тени. И сегодня я попробую их осветить.
Качество данных
Если твой техлид упрямо
Просит данные почистить –
Посылай его подальше!
Поиск должен так найти
И начнем статью про поиск мы не с поиска, а с того, ради чего все затевается. С данных. Как театр начинается с вешалки, так поиск начинается с контента, который мы будем искать. Сама мысль о том, чтобы реализовать поиск, когда данных у вас нет совсем, выглядит заведомо абсурдной. Но вот искать данные по датасету, который не был должным образом обработан, отформатирован и очищен – очень популярный паттерн. Огромное количество организаций подходят к решению проблемы реализации поиска с конца – с поискового алгоритма, полностью игнорируя этап обработки данных.
Поисковые алгоритмы – это такие рок-звезды. Все внимание направлено на них. Это – классная инженерная задача, это крутой опыт для резюме, это возможность почувствовать себя Воложем или Грином. Форматирование тысяч карточек товаров, приведение данных к общему виду, устранение дубликатов в свою очередь очень скучная рутинная задача, которую вообще можно не решать. В конце концов, если поисковый алгоритм будет достаточно хорошим, он сам разберется в той колоссальной куче мусора, которую в компании называют данными. Знакомо?
Мне – очень. Одна из главных причин того, что поисковые системы работают плохо – это плохие данные. При этом улучшение качества данных может делаться гораздо менее квалифицированными специалистами, чем разработка поискового движка. Почти всегда при анализе проблемной системы улучшение качества данных – самый низковисящий и сочный фрукт, который может принести огромный эффект.
Отчасти недооценка работы с данными строится на том, что это просто менее интересная задача, отчасти виноваты компании типа Яндекс и Google, которые структурируют хаос интернета и готовы показать более-менее адекватный ответ на любой запрос. Главное тут не причина, а факт: качеством контента зачастую пренебрегают.
Раз мы с вами условились, что делаем плохой поиск, тоже проигнорируем подготовку данных.
Отсутствие требований
Если задал разработчик
Кучу каверзных вопросов
Про нагрузку, про корзины
Про того, кто твой клиент
Так он просто маскирует
Всю свою некомпетентность
Ведь нормальный исполнитель
Должен все и так понять
Это – мое любимое! С требованиями в IT нередко бывают проблемы, далеко не все заказчики осознают их важность, но в случае поиска проблема достигает апогея. Все пользуются поиском. И скорее всего по нескольку раз на дню. И все абсолютно точно знают, что такое поиск и как он работает.
Нет, ну правда, это же очевидно?! Ну вот возьми яндекс, озон, свой-любимый-магазин и сделай так же точно. Чего непонятно?
Непонимание необходимости сбора и фиксации требований к такому “примитивному” продукту как поиск настолько велико, что мы даже не будем поднимать этот вопрос. Наш поиск будет сделан без них. Мы же компетентны, мы и так понимаем, что надо сделать.
Отсутствие метрик
Если вдруг весы на кухне
Огорчают третьей цифрой –
Наступите посильнее.
Пусть сломаются совсем!
И тогда не сможет больше
Бесполезная железка
Вас расстраивать ужасным
Поведением своим
Чтобы сделать что-то хорошо, нужно мерило. Иначе сложно дать какую-то качественную оценку сделанному. Поиск – задача, которую затруднительно проверить алгоритмически. Сложно придумать количественную метрику, которая могла бы трактоваться как качественная. Да, можно работать со скоростью ответа, с количеством товаров в поисковой выдаче, но вот разработать критерии качества этой выдачи, особенно субъективные – задача нетривиальная.
Давайте просто пропустим этот этап!
Преимущества игнорирования метрик очевидны: во-первых, никто не сможет обвинить вас в том, что поиск плох. Без методик количественной оценки любые суждения о качестве продукта будут просто частным мнением. А частные мнения можно и не принимать. Во-вторых, как уже говорилось, задача сложная. Чего тратить на неё время? В конце концов неужели непонятно, что такое поиск? А если так, то несложно убедиться, что он работает правильно. Главным критерием будет наша экспертная оценка. Сэкономленное на бесполезных метриках время можно будет потратить на развитие продукта!
Зачастую примерно так выглядит подход к метрикам: вместо внедрения полноценных процедур проверки, команды смотрят вручную наиболее частотные запросы, причем не системно, а от случая к случаю. В результате чего по системе прокатываются регресс-баги, отваливаются целые сценарии, а качество выдачи может плавать малозаметно для наблюдателя, но ощутимо для пользователя.
Думаю, в нашем кейсе все понятно, метрики пропускаем.
В этом месте мы заложили отличную основу для того, чтобы получить плохой продукт. По правде говоря, пунктов выше хватает, чтобы сделать поисковую систему достаточно плохой. Но ведь нет предела идеалу? Можно ухудшить результат ещё. Этим мы и займемся!
Царь-запрос
Если ты одним запросом
Взять не можешь нужных данных:
Вес, количество, названье
Описанье, цены, фото,
Отзыв, дату производства
И историю покупок
И наличие в Назрани
И погоду в Сыктывкаре…
То тогда ты самозванец
И вообще не программист
Если бы где-то был список подходов по работе с эластиком, отранжированный по популярности, этот паттерн стал бы абсолютным лидером. API ElasticSearch очень богато возможностями и на нем можно писать очень сложные заклинания. А если можно – то значит нужно!
Преимуществ у данного подхода очень много:
- Во-первых, одним запросом генерируется вся поисковая выдача, это очень удобно тестировать и поддерживать: запрос можно читать просто сверху вниз как книгу (иногда очень длинную). Никаких неожиданностей, все перед глазами.
- Во-вторых, мы не делаем лишних сетевых вызовов, а это оптимизация.
- В третьих — согласованность данных. И фильтрация, и ранжирование, и агрегации, и пагинация – все будет в одном запросе, а значит ничего нигде не разъедется и мы сможем быть уверены в целостности и непротиворечивости поисковой выдачи.
Да, такой запрос со временем становится очень большим, да, в какой-то момент добавление нового поискового сценария превращается в инженерный подвиг, а время выполнения мега-запроса уверенно подбирается к паре секунд на особенно неудачных кейсах. Но, может описанные выше преимущества стоят того? К тому же мы вручную проверяем наиболее важные поисковые запросы и не допустим, чтобы система на них отрабатывала плохо.
Взвесив все за и против, мы будем делать поиск одним запросом, в котором учтем все необходимое.
Исправление ошибок
Если ты когда-то слышал
От знакомого коллеги
В переполненной курилке
Что-то там про базы данных
Проверять не думай даже
Это точно так и есть!
Все знают, что эластик умеет исправлять ошибки в запросах. Ну серьезно, если вы хоть что-то про него когда-то слышали, то вам этот факт наверняка знаком. Это самый популярный миф об ElasticSearch.
Практически на каждом проекте используют эту суперсилу, чтобы победить опечатки в пользовательском вводе. И наверное нет какого-то ещё инструмента, который нанес поисковой выдаче больший урон, чем “исправление ошибок” от эластика. Я сейчас говорю о fuzzy search.
Чтобы не копировать сюда документацию, напишу кратко. При использовании этой фичи для каждого токена в запросе Elastic создает массу похожих, находящихся на расстоянии 1 или 2 (как выставите fuzziness) символов. И начинает искать по всем этим токенам сразу. Это действительно может помочь в случае опечаток, однако очень большой ценой: помимо того, что сам запрос становится дороже, в выдачу может попасть куча всякого разного, что там никто не ждал. Использование fuzzy queries похоже на неизбирательное применение антибиотиков или на ковровые бомбардировки. Какой-то положительный результат определенно может быть достигнут, но ценой колоссальных сопутствующих потерь. Эти потери можно пробовать уменьшать через использование параметра prefix_length, если мы верим, что пользователи не будут совершать ошибок в первых буквах или играя с max_expansions (попутно уменьшая вероятность того, что будет подобран верный токен). Но корень проблемы останется.
Обычно мы хотим точечно исправить ошибку, если она допущена и вообще ничего не делать, если ошибки не было, а не провести поиск сразу по сотням токенов, похожим на те, которые были в оригинальном запросе. Гораздо правильнее было бы использовать специализированные решения по проверке орфографии как на этапе очистки данных (который мы благополучно пропустили), так и перед выполнением запроса. Но это слишком долго! Да и зачем, ведь эластик исправит ошибки сам.
Добавляем секцию с fuzzy search в царь-запрос.
Вложенность данных
Схему данных составляя
Делай как учили в ВУЗе.
Пусть не смеют инструменты
Диктовать свои подходы.
В схеме главное порядок!
А о всяких там нагрузках
Пусть подумают другие.
Например вон тот девопс
Когда мы говорим о поиске в электронной коммерции, мы почти всегда имеем дело с несколькими типами сущностей. Товары, цены, наличие в магазинах. Иногда добавляются еще какие-то: например товарное предложение, особенно если имеем дело с маркетплейсами и несколькими селлерами, реализующими один и тот же товар. Могут быть ограничения видимости товаров, регионы и прочие измерения, с которыми удобнее всего работать как с отдельными сущностями. Как все это обработать?
Предыдущий опыт дает подсказку: надо организовать связи между этими объектами. Так мы избавимся от дублирования информации и сможем независимо обновлять сущности. У эластика есть инструмент join, который позволяет явно выстроить иерархию документов в одном индексе. Что может пойти не так?
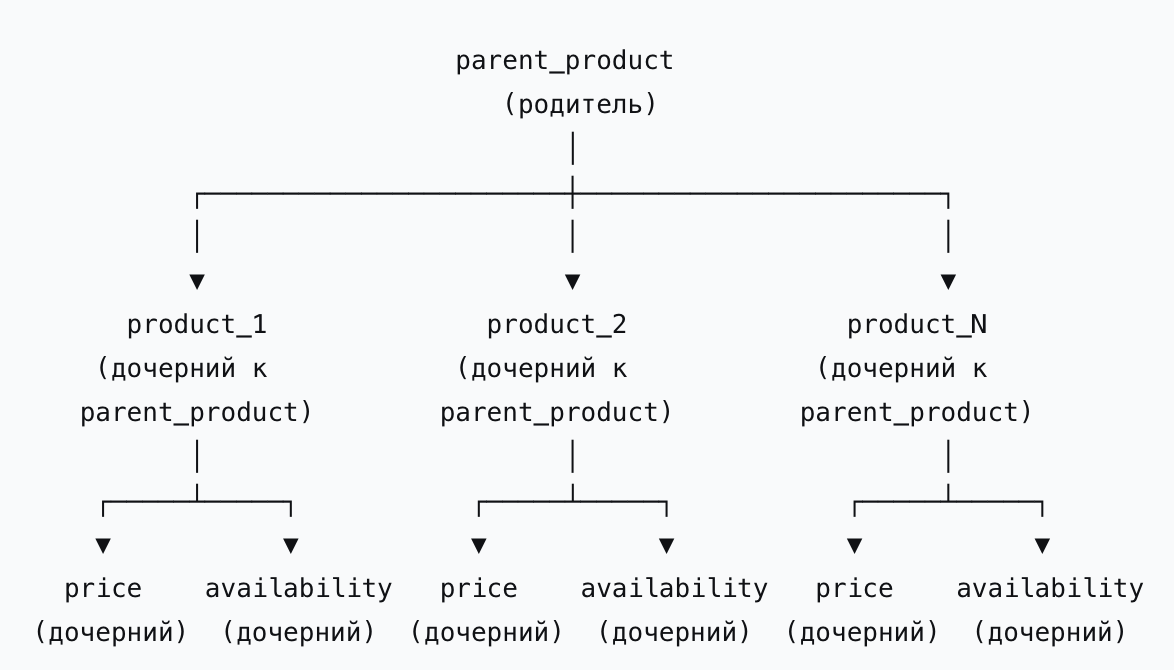
Да примерно всё… За сравнительно скромные бонусы в виде более эффективного обновления вложенных документов и экономии дискового пространства (sic!) мы получим целый набор проблем.
Во-первых, неэффективные и дико дорогие запросы, когда мы фильтруем по вложенным документам. При этом мы конечно же не будем упрощать себе жизнь и намертво прибьем логику фильтрации по цене и по наличию к основному поисковому индексу – не зря же мы добавляли туда информацию об этом.
Второй проблемой будет рассинхронизация данных. В эластике нет понятия “транзакции”, потому когда мы индексируем родительский документ с кучей вложенных, мы можем получить любое случайное подмножество документов в индексе. К счастью сам по себе ElasticSearch — надежная система, потому описанная ситуация будет происходить достаточно редко, чтобы на нее можно было не обращать внимания.
Добавив в царь-запрос несколько блоков с фильтрацией по вложенным документам, мы усложнили его до почти неподдерживаемого состояния. Плюс на некоторых запросах он работает по несколько секунд. Так держать! В этот момент мы нанесли системе достаточно вреда, чтобы её низкое качество начало быть заметным всем: и пользователям и заказчику. Самое время переходить от фазы разработки к фазе поддержки.
Жадность
Если пользователь хочет
Йогурт “персик-маракуйя” –
Забирай весь холодильник!
Там он точно где-то есть…
Поисковые алгоритмы по-разному могут формировать выдачу: стараться выбрать только абсолютно релевантные документы или брать вообще все, что хоть сколько-нибудь соответствует запросу. Первый алгоритм будет условно “строгим”, а второй “жадным”. Жадность сама по себе не является ошибкой, которую можно допустить или которой можно избежать. Никто не принимает решения “сделать поиск жадным”, это – следствие принятых ранее решений, симптом проблемы, а не проблема сама по себе. Плохой поиск почти наверняка будет жадным и почти никогда – строгим. Давайте разберем, что на это влияет.
Причина номер один: боязнь пустых выдач. Очень распространенная беда, когда хочется показать пользователю хоть что-нибудь, не оставив его наедине с пустой поисковой выдачей. Это заставляет добавлять в сценарий поиска дополнительные поля, обмазывать товары синонимами и снижать требования к соответствию результатов выдачи оригинальному запросу. Пример такого подхода видел, наверное, каждый. У нас нет орехов кешью? Покажем печенье “орешек со сгущенкой” и шоколад Ritter Sport с орехами. Если пользователю правда нужны орехи, пусть он их выковыривает.
Вторая причина – плохое качество данных. Мы здорово сэкономили на этом раньше и вот наступило время платить проценты по счетам. Некачественные тексты, ошибки, кривые названия, разный формат значений в полях. Страдать будут как сценарии текстового поиска, так и фасетного, но конкретно в текстовом плохое качество данных скорее всего также побудит нас уменьшить требования к соответствию запроса данным в индексе, чтобы подтянуть даже плохо заполненные документы.
Ну и конечно упоминавшееся выше “исправление ошибок”. Генерация кучи дополнительных токенов добавит в выдачу такую же кучу дополнительных товаров. Да, скорее всего найденное через fuzzy search будет иметь пониженный вес и окажется ниже, но и без того жирная выдача станет еще больше.
Это не все, но этого уже достаточно для того, чтобы по общим запросам в не самом большом магазине в выдачу попадали сотни и тысячи товаров. Еще хуже то, что общий запрос не получится уточнить, потому что при работе с неполным совпадением дополнительные токены с большей вероятностью расширят выдачу, чем сузят ее.
Но является ли это вообще проблемой? Давайте представим вырожденный случай жадной выдачи: на каждый запрос будет возвращаться вообще весь каталог, отранжированный в соответствие с запросом. Что не так в таком сценарии?
- Нагрузка на систему. Тут все просто: чем больше документов обработали, тем больше потратили процессорного времени, памяти и сетевого канала
- Неработоспособность агрегаций: чем по большему количеству документов мы их делаем, тем менее они эффективны. Часть агрегаций становится неудобной в использовании (цена, бренд), часть в принципе не может быть применена (свойства, специфичные для определенных товарных групп)
Столкнувшись с жадностью выдачи, мы можем сделать вид, что проблемы нет, ведь наверху нужные товары. И это будет лучше всего. Но если отвертеться не удастся, придется работать с тем, что есть.
Устранять первопричины проблемы будет очень дорого. Да и неясно, как и зачем устранять то, что является основой, ядром продукта. Потому ограничимся борьбой с симптомом: физически отрежем хвост выдаче. Пускай все товары, чей score получился ниже определенного процента от лидера, просто пропускаются. У такого решения подводных камней хватит, чтобы проложить трассу для рафтинга, но для демо итогов спринта сгодится.
Ручное управление выдачей
Если новая программа
Не работает упрямо,
Посади отряд индусов!
Пусть ишачат за нее
Пусть вручную разбирают
Каждый новый сложный случай
Это будет даже проще,
Чем нормальный код писать.
После всех надругательств, которые мы совершили с поисковой системой выше, то, что она еще как-то работает – чудо. Но теперь, когда она худо-бедно доехала до прода и её начали эксплуатировать, встал вопрос качества. По некоторым запросам поиск выдает лютую дичь, и скрыть это не удается. К демо удалось взбодрить те 20-30 запросов, на которых поиск тестили вручную, но пользователь – зверь очень непонятный и хочет он зачастую странного. Заказчик заваливает вас скринами неадекватных выдач. Скандал.
Потенциал развития системы исчерпан полностью еще до запуска, и вы понимаете, что без полной перестройки решить проблему фундаментальным образом не получится…
Скажем заказчику, что основные кейсы работают и надо заняться “тонкой настройкой”. Добавим инструменты ручного управления выдачей!
Благо тут очень внушительный арсенал того, что можно использовать! Колдовство на весах поисковых полей, пока найденные кейсы не станут работать более-менее адекватно, ручное формирование топа выдач по наиболее проблемным запросам, подмена запросов, загаживание поисковых полей в товарах ключевыми словами для влияния на TF-IDF (кто сказал, что SEO умерло?). Главное называть это “развитием”, “улучшением” и “маркетинговыми инструментами”.
Подобными паллиативными мерами можно продлевать жизнь поисковой системе долгое время, особенно если в команде достаточно низкоквалифицированных рабочих рук.
Подсказки без подсказок
Каждый должен без подсказок
Сделать мочь любое дело
И без книг, без интернета
И без вредного совета
Только так он сможет зваться
Гордым словом “Человек”
Сильная сторона людей – в том, что они ко всему привыкают. В мемуарах солдат мировых войн кошмары с передовой теряют краски и становятся ежедневной рутиной. Так и наш поиск: и пользователи и заказчик привыкнут к нему, если мы будем чинить наиболее дикие кейсы более или менее быстро. Так что очень скоро мы пройдем период “стабилизации пилота” и встанем на рельсы здоровой продуктовой разработки.
Следующей важной фичей, которую захочет продукт почти наверняка будут поисковые подсказки – если конечно вы не сделали их ранее. Подсказки — это пример задачи, которую можно очень легко сделать плохо, и мы не упустим такую возможность.
Лучший вариант – и я рекомендую придерживаться его – просто продублировать в подсказках поисковую выдачу по запросу, который пользователь вводит. Вызывать их лучше без всякого debounce, вот прямо сразу, и показывать товары, которые найдутся. Пользователь набирает “кар” – покажите первые пять товаров по этому запросу, даже если он не закончил набирать запрос.
У такого решения сплошные плюсы:
- 100% переиспользование кода поиска. Лучший код – это код, который не написан!
- Пользователь сразу получит выдачу и сможет купить товар сразу, не делая лишних кликов. Это точно поднимет конверсию
- Разработка и внедрение очень быстрые! При желании можно управиться за неделю. Начальству такое точно понравится.
Подход хорош всем, но если вдруг заказчик упрется рогом и потребует текстовые подсказки “как у всех”, придется попотеть. Но и тут есть хороший вариант. Будем сохранять статистику предыдущих запросов, которые делали в нашу систему и выводить в подсказках их по подстроке. Что-то типа такого:
SELECT query FROM suggests WHERE query LIKE ‘#QUERY#%’ ORDER BY count LIMIT 5Это все еще очень просто и тут уже совсем не отвертеться. Это реальные запросы реальных пользователей с реальным потребительским интересом. И это точно будет работать, если:
- Пользователи ищут то, что вы готовы им предложить
- Пользователи пишут хорошо сформированные запросы без ошибок. Они назубок помнят как пишется Head&Shoulders, Meizu и готовы писать их на языке оригинала, а не транслитом
- Пользователи никогда не напишут ничего крамольного в поиск, даже увидев, что их запросы попадают в подсказки
- Не стоит ожидать каких-то новых товаров или существенного расширения ассортимента на новые товарные группы
Очень скромный список допущений для внедрения такой классной фичи. Продано! Ну а чтобы все получилось с гарантией, подходы можно объединить. Тогда подсказки будут выглядеть солидно как у больших компаний.
Да, такие подсказки будут полезны где-то на 10% от возможного и лишат нас мощного инструмента, позволяющего познакомить пользователя с ассортиментом, помочь ему писать более точные и корректные запросы или превращать полнотекстовый поиск в гораздо более дешевый фасетный. Но главное, что они будут классно выглядеть в продуктовых презентациях!
Мода на ИИ
Если нас заменит робот,
То давай работать бросим.
Делегируем железке
Каждый следующий шаг!
Ну а если он болезный
Все осилить сам не сможет,
То ему же только хуже.
Дольше будет нагонять
Все низко висящие фрукты сорваны. Потенциал развития поисковой системы очень ограничен. Но, к счастью, технологии искусственного интеллекта бурно развиваются, так что мы можем выжать из этого пользу. Заказчик точно будет в восторге. Больше скажу, скорее всего он сам придет с предложением внедрить куда-то ИИ. Так хочется сказать на интервью в РБК, что “внедрение решений на базе технологий искусственного интеллекта увеличило выручку на 30%”. Тем более, что классические инженеры долго возятся с невнятным результатом, очевидно, что надо пробовать disrupt подходы. Так что тут вы будете на одной стороне.
Фича с ИИ обязательно должна быть громкой! Никого не впечатлить автоматизацией очистки данных, пусть эта задача и покрылась толстенным слоем пыли. Ярче всего будет что-то сделанное именно в поиске. Брать лучше всего современные мощные LLM-ки. Во-первых с ними меньше возни и можно не тратить много времени на скучную математику, во-вторых это модно. Заказчик будет счастлив, что он на острие прогресса и под капотом у его проекта наиболее эффективные инструменты на рынке.
Внедрение подобных технологий имеет свой четкий жизненный цикл:
- Подбираем удачный сценарий. Пусть он будет очень узким и локальным, главное, чтобы положительный результат был виден без метрик, просто невооруженным глазом.
- Делаем очень маленький пилот, может быть даже просто демо. Заявляем, что решение готово к эксплуатации и станет прорывом. Зрители рукоплещут.
Очень быстро оказывается, что масштабирование встанет в копеечку. Но это уже не ваша вина. Зачем было просить делать прорывные вещи, если не можешь их себе позволить? Но и признавать такое обидно, так что обе стороны процесса смогут засчитать себе успех: у заказчика современные ИИ решения, у исполнителя – success кейс по внедрению искусственного интеллекта в поиск в крупном e-commerce продукте. Win-win!
Конечно описанное выше не значит, что ИИ не может принести пользу. Да, многие успешные успехи надо отмывать от маркетингового буллщита, но и так остается много сфер, где его внедрение может быть эффективно. Например:
- Очистка и подготовка данных
- Формирование пула поисковых подсказок
- Персонализация выдачи
И это естественно не все. Но покуда наша цель “сделать плохо”, мы возьмем самый дорогостоящий и сложный вариант, надуем пузырь завышенных ожиданий и будем выдавать грандиозный провал за успех, пока все вокруг в это не поверят.
Заключение
Может показаться, что статья – это набор шуток на околотехническую тематику, но увы, каждый пример вдохновлён каким-то реальным проектом. За каждым советом скрывается конкретное решение, которое кто-то придумал, защитил, реализовал, получил за это деньги и эксплуатировал. Некоторые эксплуатируются и по сей день.
Хуже всего то, что описанные проблемы умеют маскироваться. Поиск «вроде работает», пользователи «вроде находят» — а тем временем конверсия тихо проседает, нагрузка на инфраструктуру растёт, а команда тратит всё больше времени на ручное тушение пожаров. Если что-то из описанного показалось знакомым — скорее всего, это не единственная проблема в вашей системе. Они редко приходят поодиночке. Но у каждой из них есть решение.
Можно ли, вооружившись списком вредных советов, просто инвертировать его и получить хорошие? Не совсем — между «не делай плохо» и «делай хорошо» лежит пропасть, которую не перешагнуть простым избеганием конкретных ошибок. Потому в следующей статье я постараюсь поделиться рецептами, которые помогают принимать правильные решения при проектировании поисковых систем.