Микросервисная архитектура давно прошла пик хайпа, вышла на плато продуктивности и из модной штуки на острие прогресса стала must-have. Все знают, что такое микросервисы. Все их применяют.
Микросервисы победили
Почему? Ну… на то есть причины. Лучше всего на этот вопрос ответит иллюстрация. Давайте представим себе стандартный веб проект. Он пока совсем маленький, зеленый. Естественно монолит. Он целиком помещается в голову всех участников процесса, работать весело и легко. Такой дружеский стартап.

Проект привлекает инвестиции, увеличивается команда, появляются специализации. Объем кода и функциональности потихоньку растет, никто уже не может удержать проект в голове. Это еще не зрелость, но и не юность

В какой-то момент рост становится неконтролируемым. В нем куча дублирующейся логики, централизованного ревью уже давно не проводится. Некоторые его участки начинают плохо пахнуть, а в главной сущности проекта больше двух тысяч строк!
Вдобавок где-то тут приходят высокие нагрузки. И вопрос качества из абстрактного становится очень важным.
А что вообще такое “высокие нагрузки”? Чем они отличаются от низких или средних? Точного ответа нет. Можно попробовать привязаться к количеству RPS: пятьсот, тысяча, десять тысяч. Но и это не ответ: во-первых у кого-нибудь всегда будет больше, во-вторых запрос запросу рознь. Можно получать сущность по ID из кеша, а можно делать дорогостоящие вычисления. Потому давайте сегодня воспользуемся очень простым определением: высоконагруженным проектом будет называться такой проект, который не справляется с нагрузками. Такой, где вам надо что-то предпринимать, чтобы справиться с потоком запросов: просто добавить памяти или ядер нельзя. Надо прямо что-то менять.
А что будет, если не менять? Ну скорее всего что-то такое. Смерть. Проект сломается под собственным весом и похоронит под руинами своих авторов.
Такой итог обычно никого не устраивает. Часто тут происходит — я уверен, большинство так или иначе с этим сталкивались — что-то такое: проект делится на микросервисы.
И вот этот вот переход от толстого неказистого монолита — это Грааль современной разработки. Почти все этим занимаются. Выходят статьи, выступления, об этом рассказывают на курсах. Даже в ВУЗах наверное уже преподают.
И целесообразность этого перехода я сегодня поставлю под сомнение.
Что такое микросервисная архитектура?
Перед тем, как двигаться дальше, давайте определимся с определениями. Что такое микросервисная архитектура? Вопрос кажется простым: это архитектура, основанная на микросервисах.
Окей, что такое “микросервис”. Ээээ… это маленький сервис. Было бы сильно проще, если бы в IT была принята система СИ: можно было бы сказать, что это одна миллионная сервиса. Но такого нет. Надо думать.
Определения микросервисов через “микро”, т.е маленькость плохи, так как ничего не объясняют, а лишь противопоставляют себя традиционным “большим” проектам. Но даже так возникают вопросы:
- Каким должен быть микросервис, чтобы считаться “микро”?
- Сколько нужно микросервисов, чтобы сказать “у нас микросервисная архитектура”?
На первый вопрос волевым решением зафиксируем такой ответ: микросервис — это приложение, которое отвечает принципу единственной ответственности. У нас должна быть только одна причина, зачем в него нужно вносить изменения.
Второй вопрос с подвохом. Очевидно, что нет какого-то конкретного количества: 1, 2 или 42. Легко ответить на него, когда в микросервисах всё и нет ничего, кроме них, но так же бывает не всегда. Давайте считать, что половина бизнес-логики и больше дает нам право считать, что архитектура – микросервисная.
Теперь, когда мы определились с дефинициями, можно двигаться дальше.
Что в микросервисной архитектуре хорошего?
О, это простой вопрос. Ответ на него должны знать все назубок. Поехали!
- Можно взять технологию, лучше всего подходящую под задачу
- Инкапсулирует работу с доменом — чистый код
- Легко локально запускать, легко тестировать.
- Быстро собираются, легко релизятся.
- Позволяют горизонтально масштабировать отдельные части системы.
- Реализует разные нефункциональные требования к разным частям системы
Вау! Выглядит круто! Наверное поэтому микросервисы и популярны.
Но что, если я скажу, что в небольшом и даже среднем проекте микросервисная архитектура будем злом? И что если вы внедрите микросервисы в монолит, вы столкнетесь со значительным количеством новых проблем, решая проблемы, которых у вас не было?
Но прежде чем приступить к минусам, предлагаю критически рассмотреть плюсы микросервисной архитектуры.
Что там с плюсами микросервисов?
Пойдем прямо по порядку. Возьмем каждый тезис из списка выше и разберем детально то, что на самом деле скрывается под утверждением.
Можно взять технологию под задачу
Вот как мог бы выглядеть стек нашего проекта, жизненный цикл которого мы разбирали выше:

Стек скучный, прям до зубовного скрежета. Тут даже обсуждать нечего…

Ой-ей! Команды могут брать технологии по своему усмотрению и тянуть модные решения. Стоит немного потерять концентрацию, вы можете оказаться в такой ситуации.
Становится сложно писать общие библиотеки, поддерживать весь этот зоопарк. Возрастает bus factor: если у вас во всей компании только один эксперт по MongoDB, у вас большие проблемы, когда он уйдет.
С этим можно — и нужно — бороться. Есть множество инструментов: технический радар, внутренние семинары, строгий архитектурный надзор. В конце концов можно стукнуть кулаком по столу и сказать “вот наш стартовый стек, мы останемся на нем”.
Но даже последнее не поможет. Даже тот стартовый стек, который у вас был, начнет расползаться по мере запуска новых микросервисов. Пока вы их выпускаете, выходят новые версии инструментов, языков и фреймворков. И приложения, которым год и больше, написаны на каких-то других технологиях, не на тех, которые вы используете сейчас.

Да, с этим тоже можно работать. Проблему можно решить, важен лишь вопрос цены, которую вы готовы заплатить. Важно понимать то, что дорога к микросервисной архитектуре ведет через зоопарк и к этому надо быть готовым.
Микросервис инкапсулирует работу с доменом
Это один из ключевых тезисов, почему микросервисы лучше. В монолите всё связано со все. А в микросервисах такого не будет. Домен упакован, все связи только через интерфейсы и контракты.
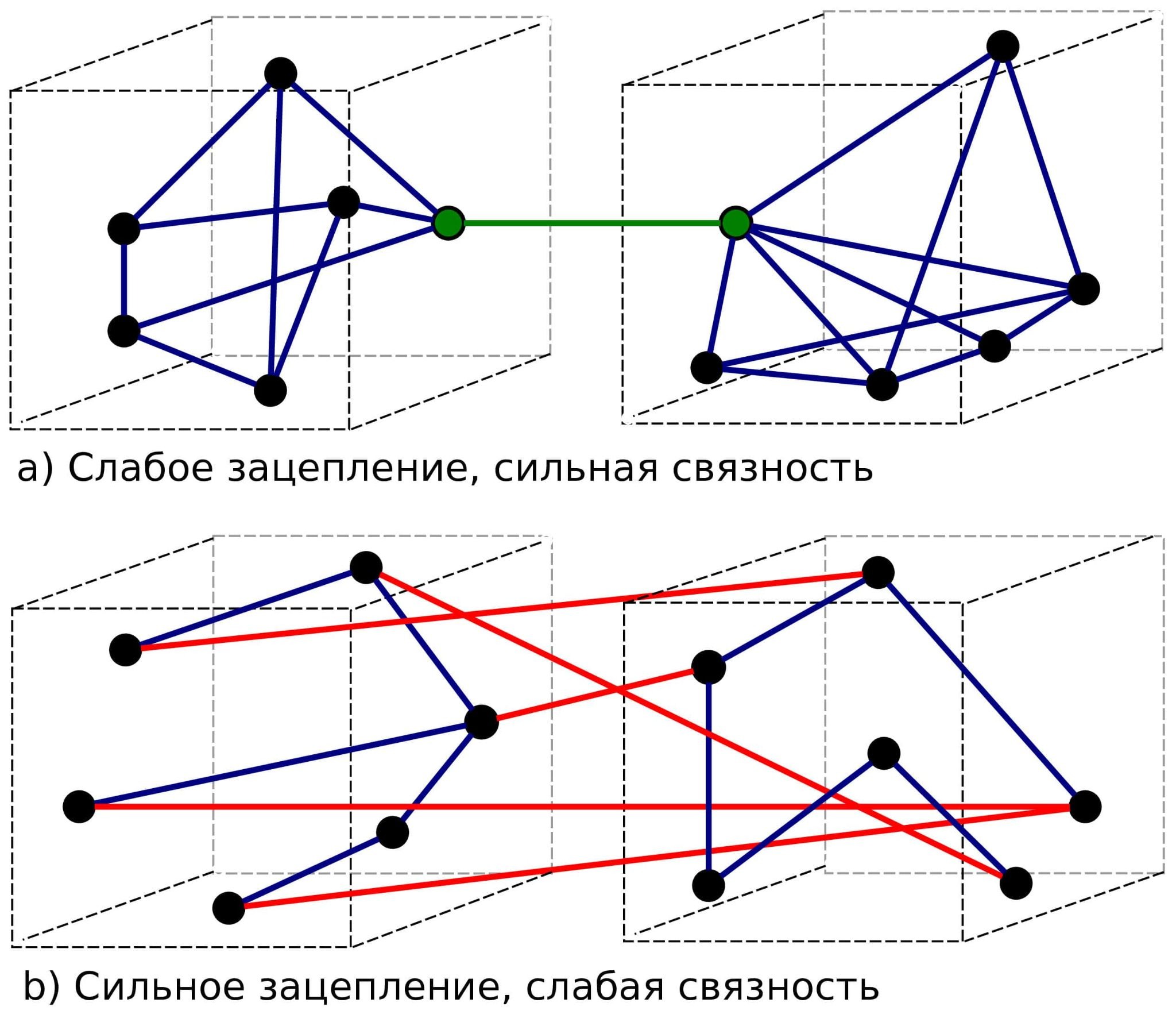
А что, если мы разобьем проект на модули, отвечающие за тот или иной аспект системы? Буквально так нас просят писать код в книжках, многие из которых стали классикой еще в прошлом тысячелетии!

Спагетти-код не является неотъемлемым свойством монолитной архитектуры. В недостатки такой архитектуры и соответственно в достоинства микросервисов заносят то, что люди плохо пишут программы. Мы можем разделить монолит на домены и построить взаимодействие между ними на основе ограниченного набора интерфейсов.
И разумеется мы так и поступим. Теперь монолит гораздо более управляемый и совсем не похож на вонючую коричневую кучу из картинки в начале поста
Более простое тестирование и релизы
Тут все просто. Буквально.
Тестировать микросервисы — просто.
Релизить микросервисы — просто.
Все это ровно до тех пор, пока мы не сталкиваемся с фичой, затрагивающей более одного микросервиса. А дальше — ад с версиями и одновременной раскаткой нескольких сервисов для сложных фич. И кошмар с зияющими дырами в экспертизе, когда надо найти человека, готового протестировать фичу в четырех сервисах.
А что с монолитом? Монолит действительно сложнее поднять, чем любой отдельный сервис, но пройдя эту процедуру, мы получаем бонус в виде бесплатного e-2-e тестирования. А сложности, связанные с регресс багами мы в большинстве своем порешали на прошлом этапе, разбив его на модули.
То же самое с релизами. Они могут быть большой проблемой, если у нас в коде месиво. Но правильно организованный монолит приведет к минимальному количеству конфликтов и его релизы будут немногим сложнее релизов отдельных микросервисов.
Независимое горизонтальное масштабирование
Хорошо. Ну а что насчет масштабирование системы? Тут у микросервисов все гораздо лучше.
Нам снова нужна визуализация. Давайте представим себе такую картину: в онлайн-магазине прилег модуль каталога.
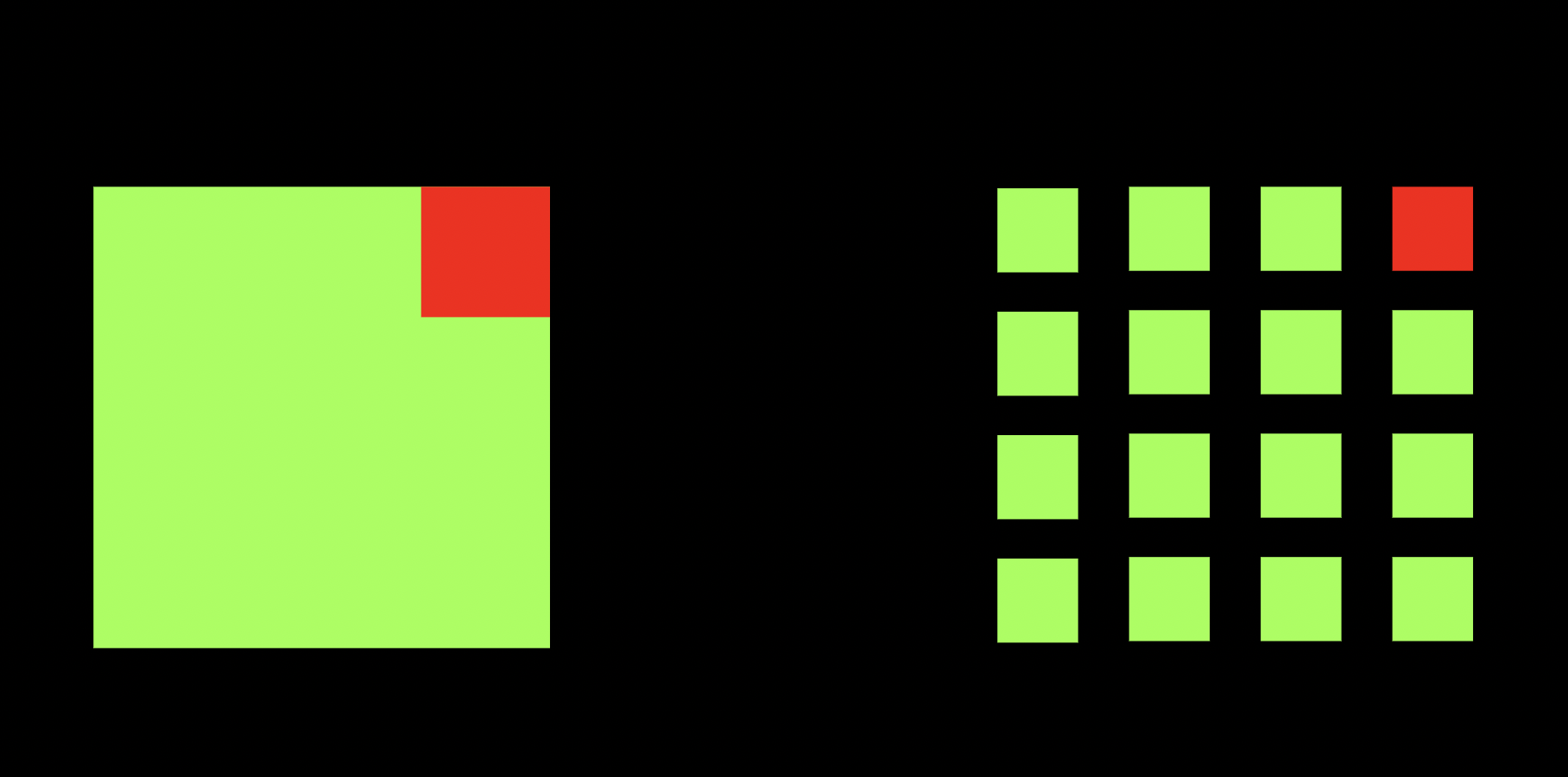
Что будем делать? Будем масштабироваться!
Каталог в виде микросервиса можно отмасштабировать отдельно, а вот монолит, увы, придется целиком.
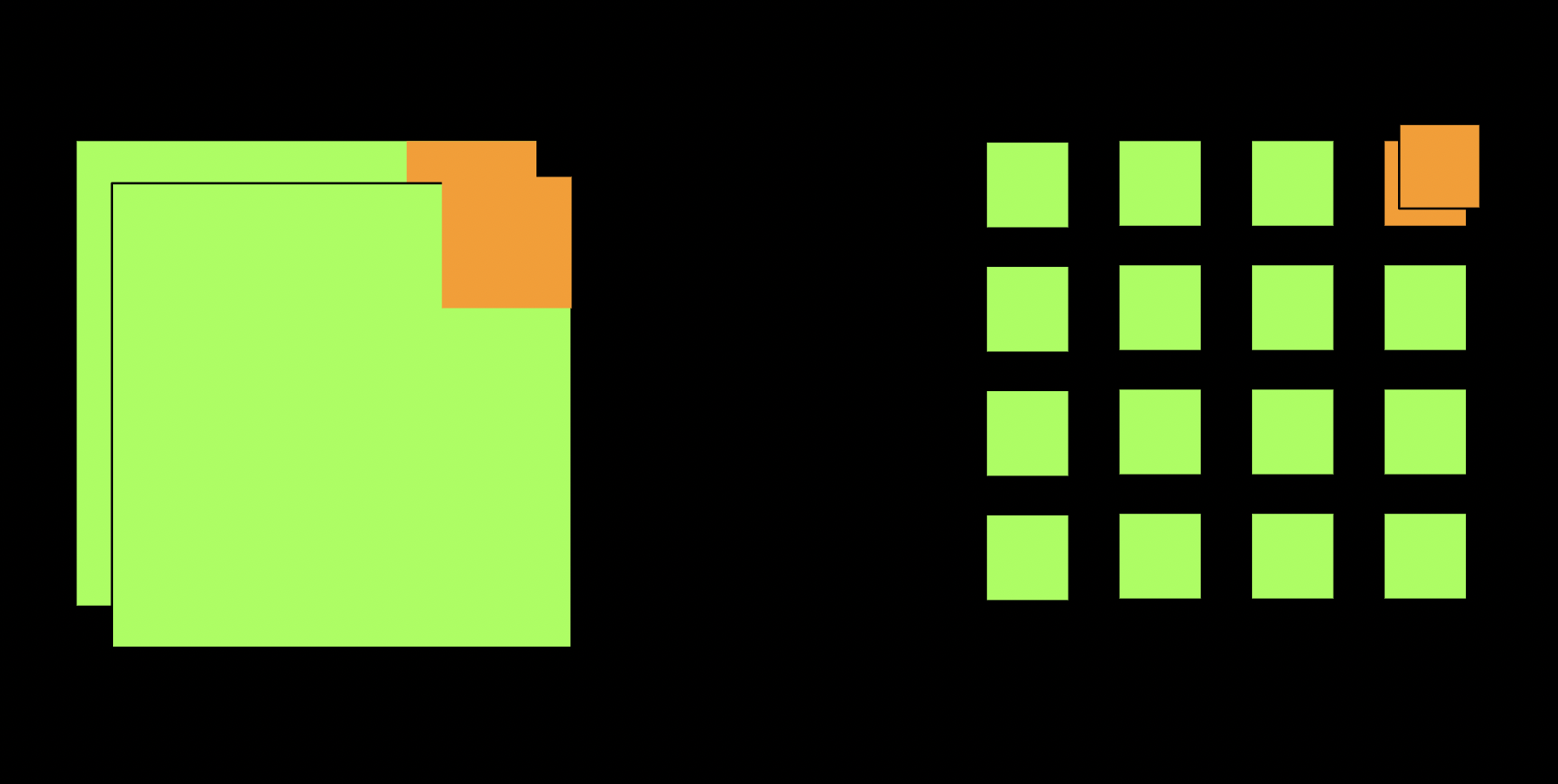


Если сравнивать квадратики по площади, очевидна победа микросервисов. Нам пришлось выделить сильно меньше ресурсов в случае микросервисной архитектуры.
Что тут не так?
- Во-первых чудес не бывает. Одинаковая нагрузка требует +/- одинакового количества железа, если у вас там +/- одинаковый код
- Зачастую масштабировать мы хотим не приложение, а хранилище. И тут микросервисы или монолит вообще не при чем
В частности, когда мы говорим про каталог и поиск, с высокой долей вероятности, они будут жить в эластике, отдельно от основной базы и масштабировать вы будете сам эластик, а не сервис, работающий с ним.
Разные нефункциональные требования к разным частям системы
Хорошо, есть еще один, последний аргумент. Микросервисы позволяют поддержать разные НФТ к различным частям системы. Например:
- Надежность 99.9999%
- Соответствие ISO, ГОСТ, законодательным актам
- Необходимость запуска в определенном контуре
- Специфический профиль нагрузки (CPU-bound, mem-bound, GPU)
- Необходимость жесткого разделения ресурсов системы
- … и так далее
Что тут не так? А тут все правильно! Это — единственное, что без микросервиса сделать не получится. Вот прямо нет способа сделать что-то подобное иначе.
Я бы даже сформулировал это так: это главная и основная причина, почему микросервис должен появляться.
А что с микросервисами не так?
Окей, в этом месте мы сформулировали, что преимущества микросервисов не настолько велики, как могло показаться. Но если ли в них минусы? Что если я возьму и разделю наш сияющий модульный монолит на микросервисы?
Здесь нас ждет целый комплекс проблем! Давайте разбираться…
Сеть
Начнем с того, что картинка выше лжет. И лжет не в деталях, а прямо в самом главном. На самом деле наша система теперь выглядит так:
Теперь все связи между этими квадратиками происходят в сети. И это мало того, что ненадежно и не гарантировано, так еще и долго. Что происходит при сетевом вызове? Это хороший вопрос на собеседование! И чем лучше ты знаешь сети, тем больше там пунктов. Возьму на себя смелость ограничиться вот таким списком:
- DNS Lookup
- Открытие соединения
- Сериализация запроса
- Отправка данных по сети
- Десериализация запроса
- Выполнение какого-то кода
- Сериализация ответа
- Отправка ответа по сети
- Десериализация ответа
- …это далеко не все (фаерволы, прокси, балансеры, аутентификация)
Это не все, но это уже много! Давайте еще раз посмотрим на этот список, только выделив главное:
- DNS Lookup
- Открытие соединения
- Сериализация запроса
- Отправка данных по сети
- Десериализация запроса
- Выполнение какого-то кода
- Сериализация ответа
- Отправка ответа по сети
- Десериализация ответа
- …это далеко не все (фаерволы, прокси, балансеры, аутентификация)
На самом деле мы хотели только это!
Да, в абсолютных цифрах это выглядит не страшно, но в конечном счете все складывается в реальные задержки и затраты. У меня есть прекрасный пример из опыта. У нас была процедура, которая стояла на критическом пути и мы хотели выполнять ее за 10мс или меньше. И на “смазку” в виде сетевого взаимодействия мы тратили 3-4мс. Почти половина всего отпущенного времени!
Целостность данных
Чем больше у нас движущихся частей, тем больше может быть ситуаций, когда что-то идет не так. Вот например мы хотим, чтобы микросервис отвечал за конкретное время и ставим таймаут. Но он ходит в другой, тот в другой и так далее.
Так мы попадаем в таймаутную воронку
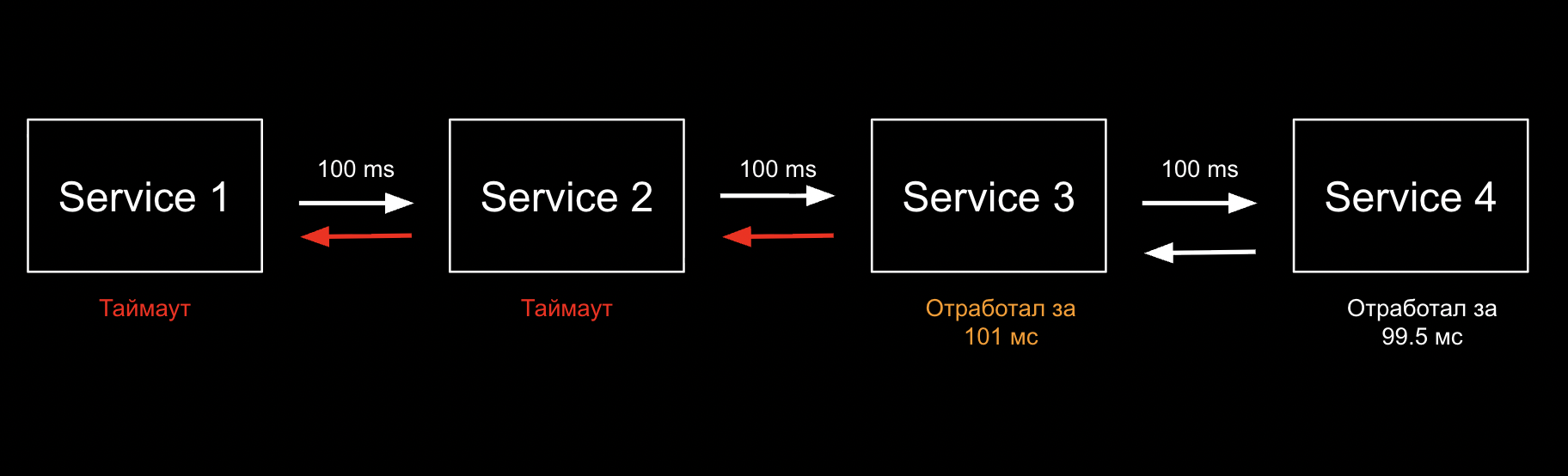
Мы можем начать играть со временем таймаутов, делая стенки воронки более пологими — и снимем часть симптомов
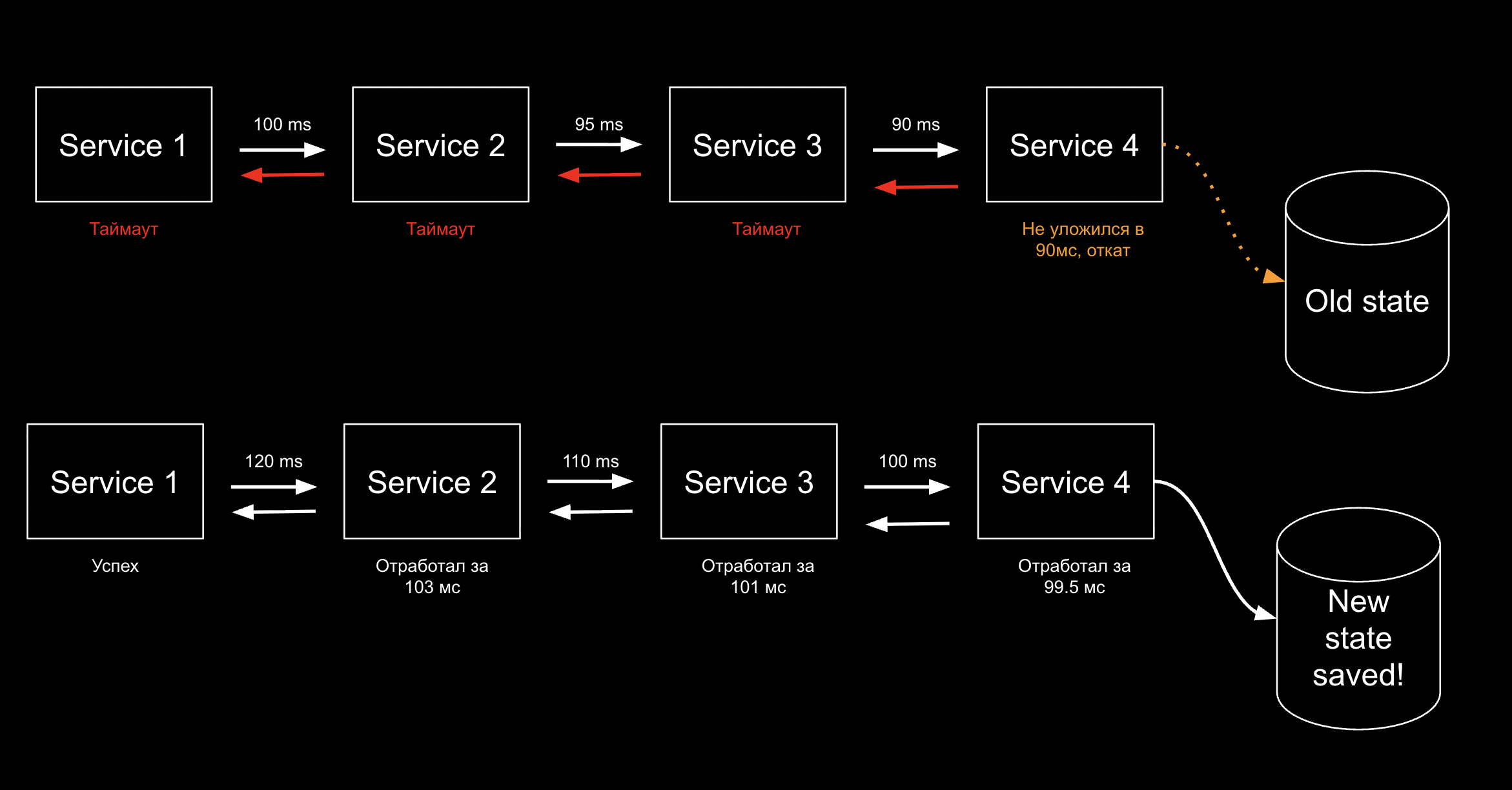
Но и ситуация может становиться сложнее, делая простые решения нерабочими. В общем случае основная проблема тут в том, что надо думать и что-то предпринимать.
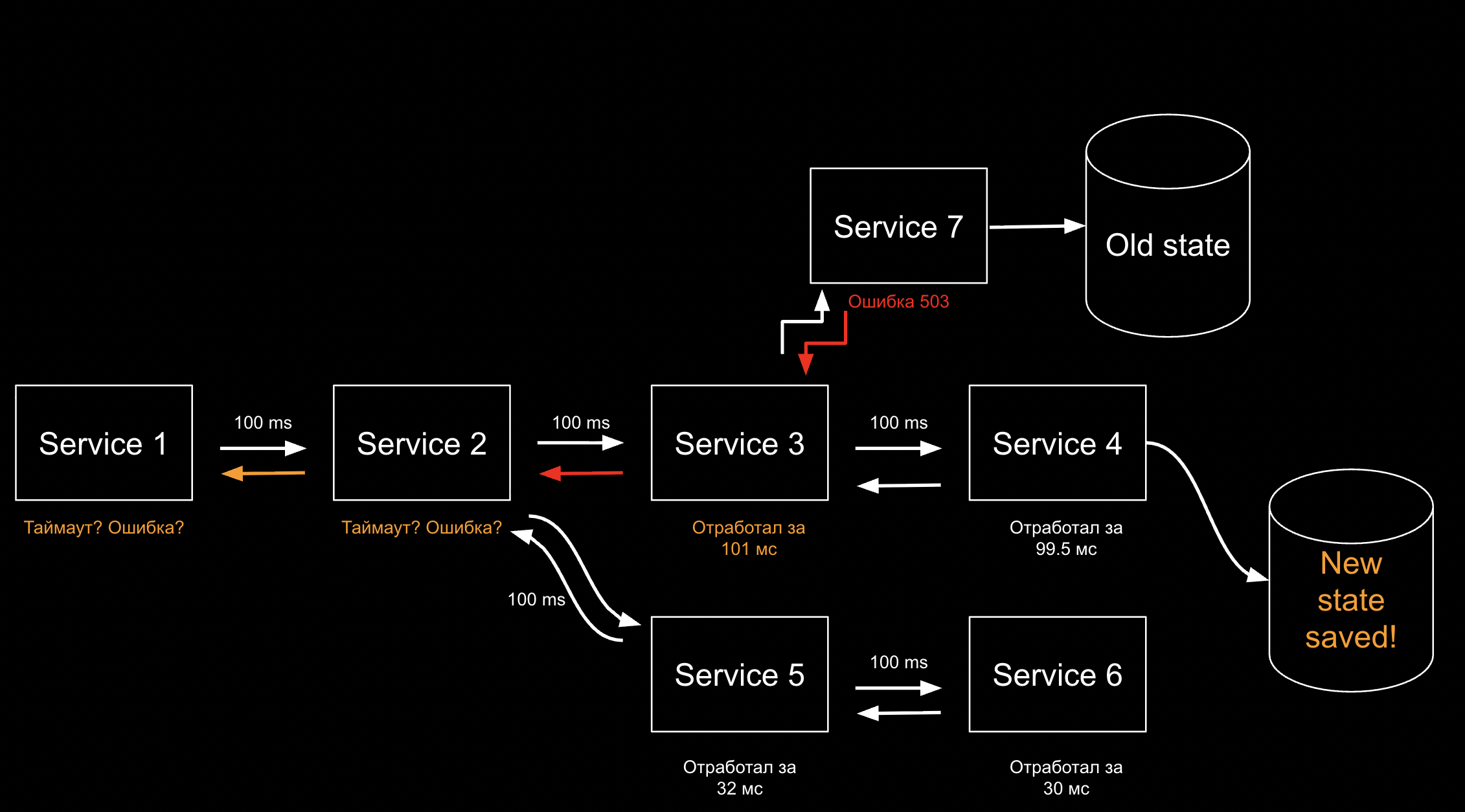
И это все достаточно простые кейсы, можно сказать, на пальцах. Но уже по ним видно, что для микросервисного приложения нужны какие-то совсем другие подходы к проектированию, чтобы система была устойчивой.
Проблема появилась не вчера. И инструменты для ее решения — есть. Давайте посмотрим на них:
- Распределенные транзакции
- Двухфазный коммит
- SAGA
- Компенсирующие транзакции
- Eventual consistency
- Graceful degradation
- Повторные запросы
Про распределенные транзакции долго говорить не будем. Главное, что надо про них знать — это то, что вы меньше всего хотите, чтобы они в вашей жизни вообще были. А вот другие подходы как будто попроще.
Ну вот например retry. Что-то пошло не так? Сделаем retry! Что вообще может быть проще? И что может пойти не так?
Ну, тут тоже есть свой список подводных камней
- Идемпотентность – не повторяй то, что боишься выполнить дважды
- Circuit breaker – чтобы не положить свою систему повторами, нужен предохранитель
- Увеличение задержек – делая что-то дважды, будь готов ждать дольше!
Неприятно? То ли еще будет! Давайте усугубим ситуацию. Попробуйте рассчитать uptime вот такой, достаточно простой системы:
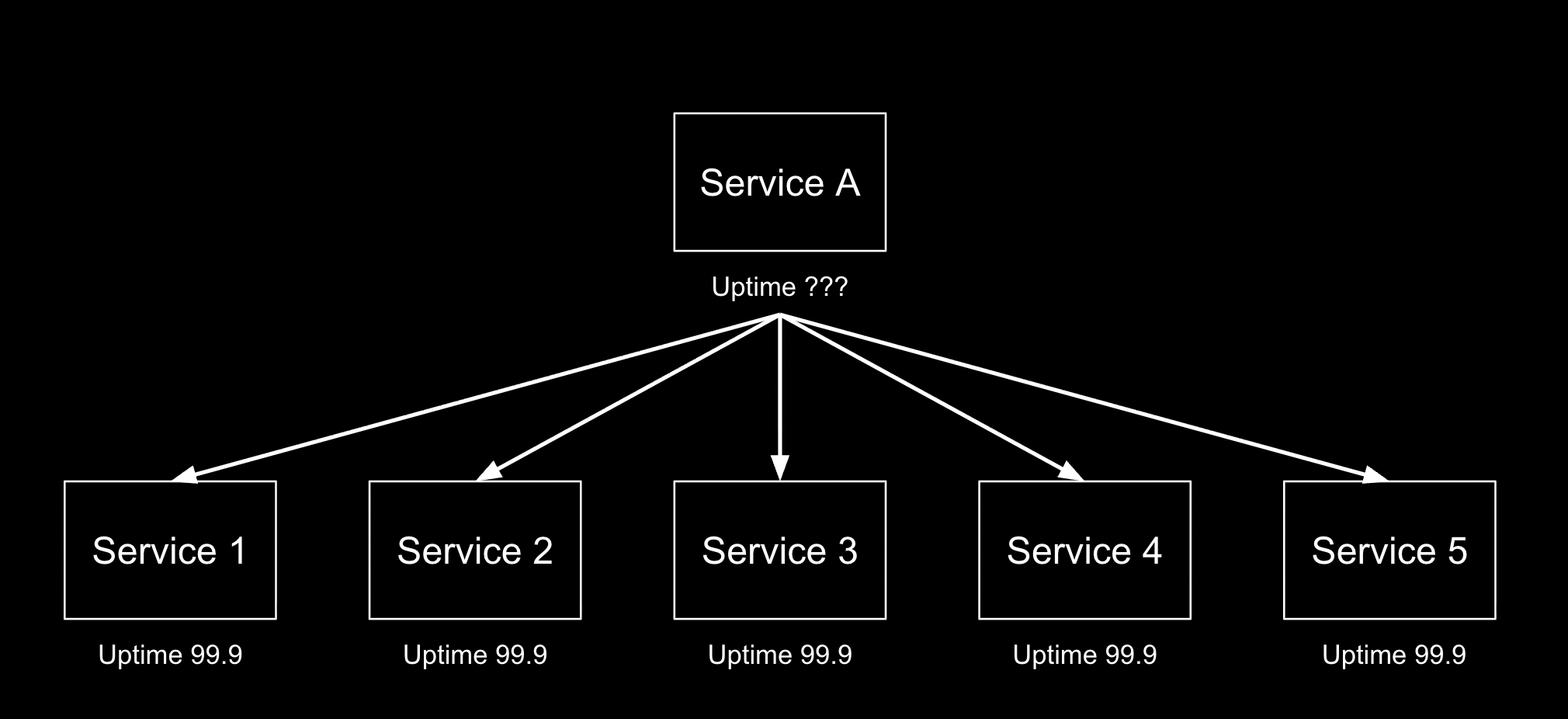
Логика и здравый смысл подсказывают, что надежность системы равно надежности наименее надежного компонента. Но в мире микросервисов логика и здравый смысл нам не помогут. На самом деле uptime системы будет равен перемножению uptime ее компонентов
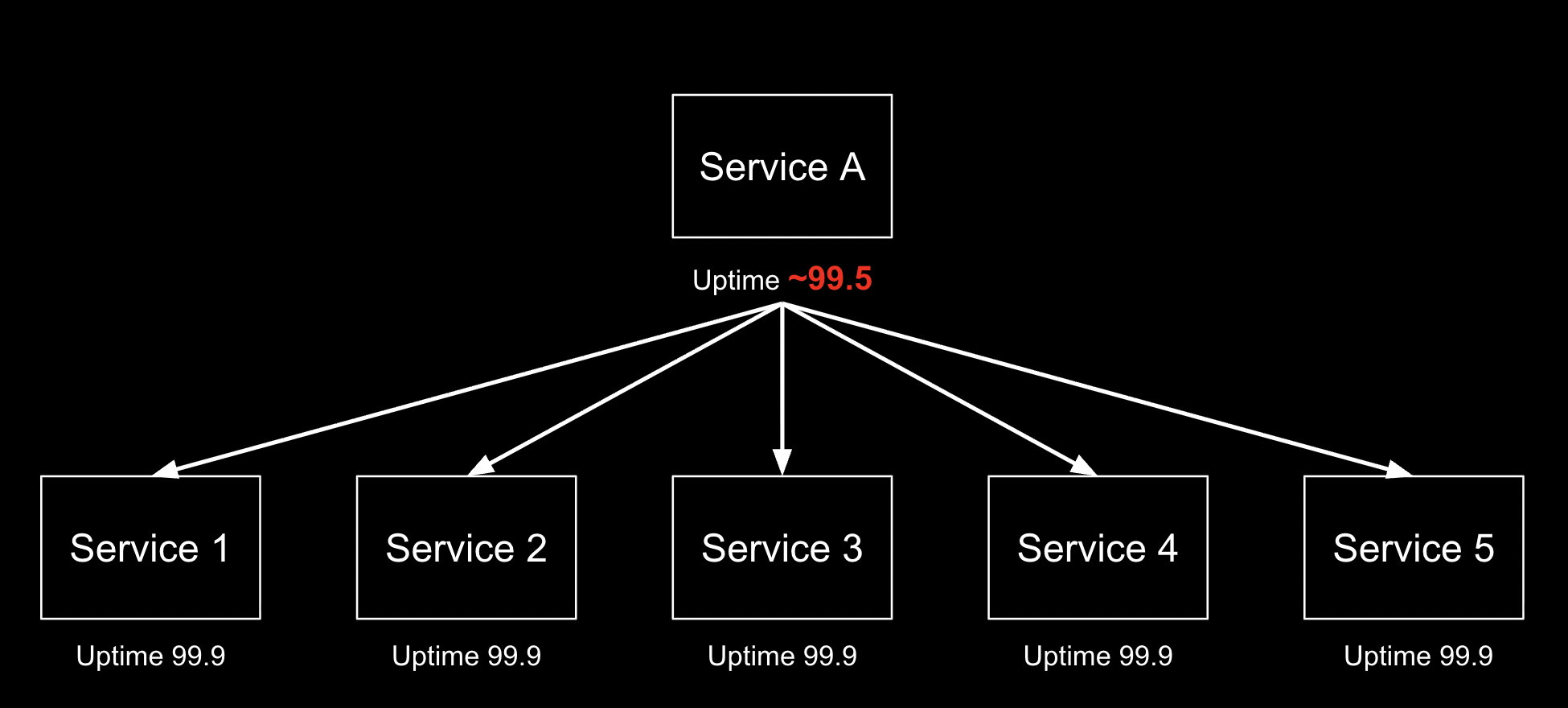
Что с этим можно сделать? Можно просто смириться; и если вы можете себе это позволить — это лучшее решение. Но обычно надо что-то предпринимать.
Первое, что мы можем сделать – это внедрить Graceful Degradation, выделив те части системы, которые могут упасть и те, которые не могут. И при падении первых мы будем выживать и работать дальше
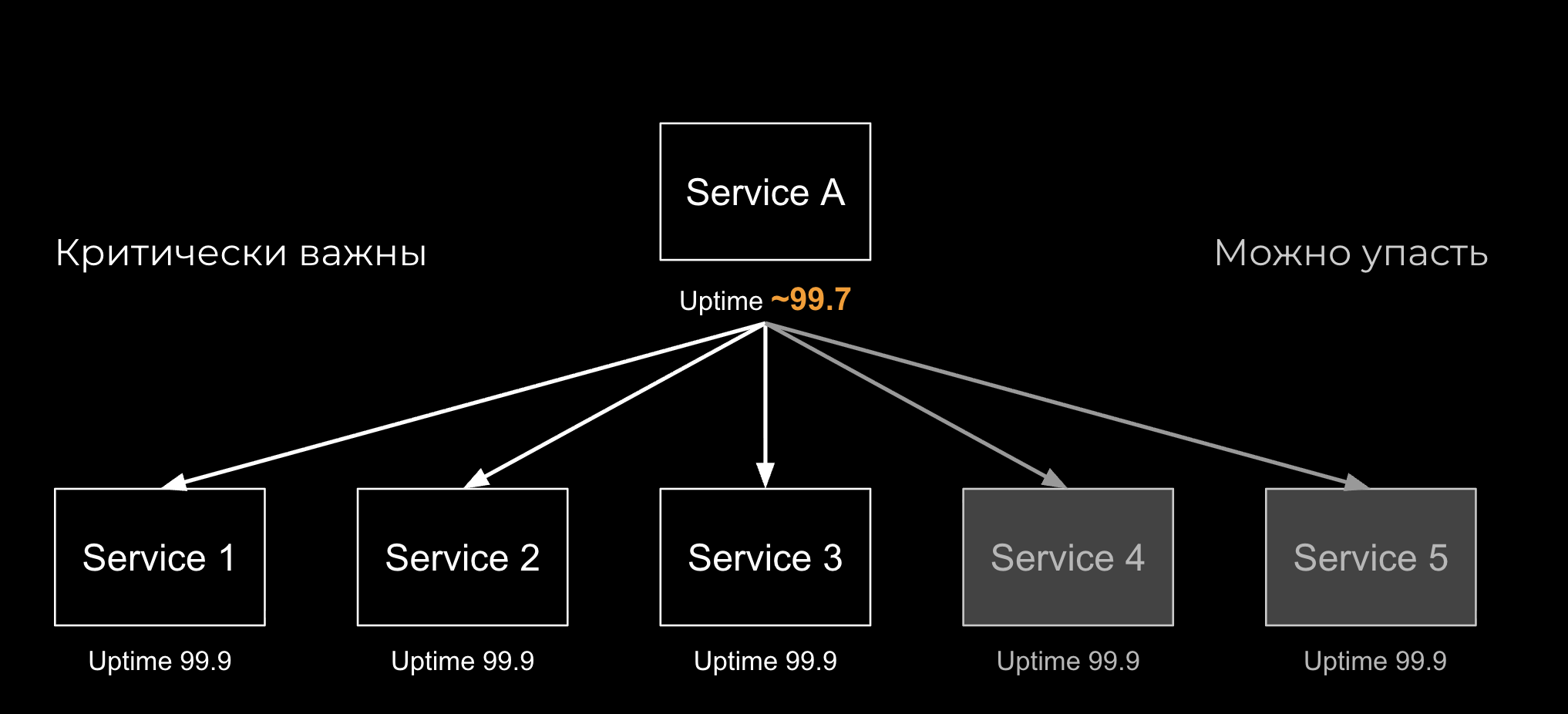
Ну и для тех частей системы, где падать нельзя, мы сделаем retry. Нам придется подумать над идемпотентностью, система и код станут сложнее, но зато мы сможем приблизиться к заветной цифре
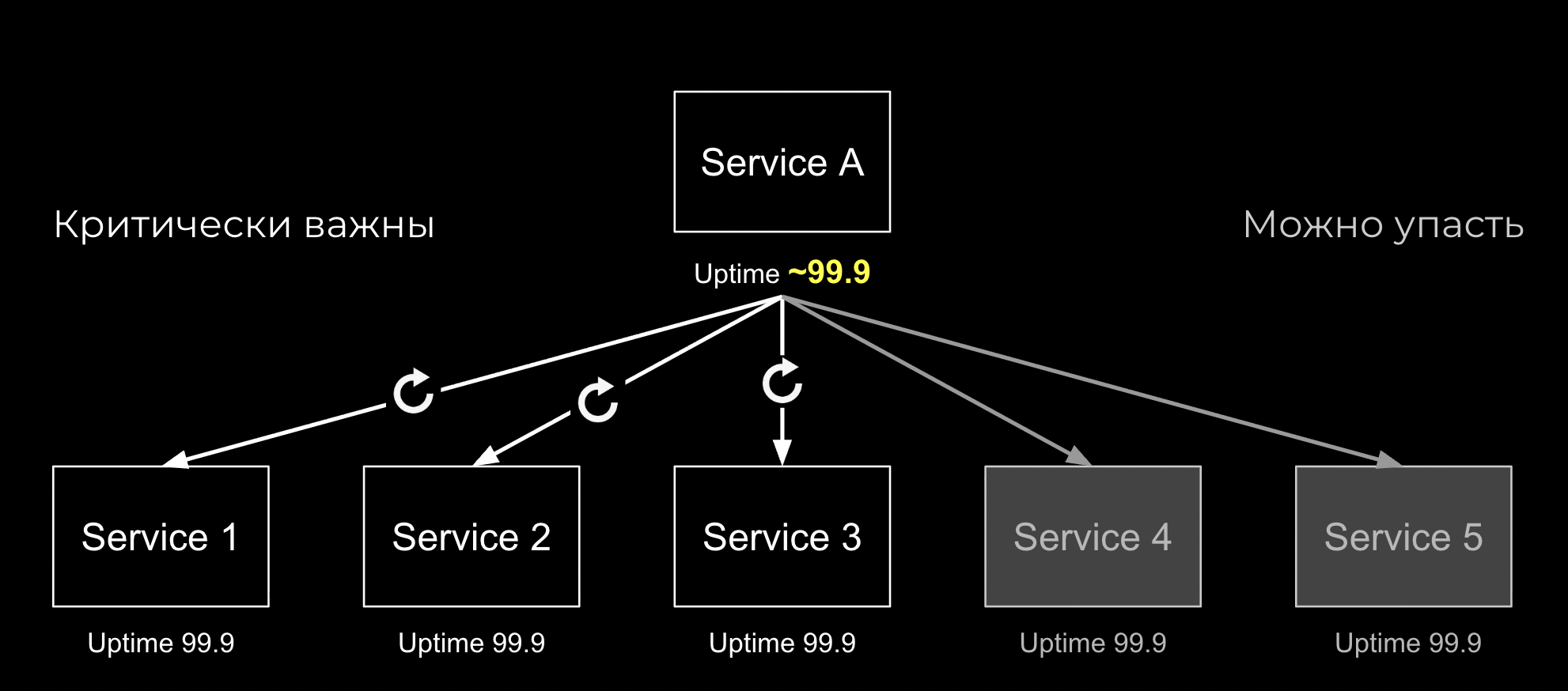
Вот это вот, что я рассказываю, это совсем по верхам, прямо базовая база, проще некуда. Но уже гораздо сложнее, чем было в монолите. И гораздо неприятнее
А почитать подробнее про повышение надежности распределенных систем можно в статье Яндекса математика надежности
Очень хочется остановиться, но это далеко не конец! Что еще нас ждет на пути перехода к микросервисной архитектуре:
- Распределенный трейсинг
- Проблемы с задачами, затрагивающими несколько микросервисов
- Больше сопутствующих расходов (мониторинги, CI\CD, дополнительные вычислительные ресурсы)
- Кратно выше потребности в DevOps
- Выше требования к квалификации специалистов
Про все это можно было бы поговорить еще, но тогда, боюсь, статью не удастся закончить. Хочется какого-то вывода, простой инструкции, как быть в этом жестоком мире.
Что ж, у меня он для вас есть. Вот простой чек-лист, который позволит жить долго и счастливо, не заходя на поляну инженерного ада.
- Готовьте монолит правильно (“чистый код” в помощь)
- Можете жить на монолите – живите на нем
- Можете не делать микросервис – не делайте его
- В остальных случаях дозированно применяйте микросервисы
Примерный вид неомонолитной системы
Система, построенная на принципах выше, будет выглядеть как-то так:
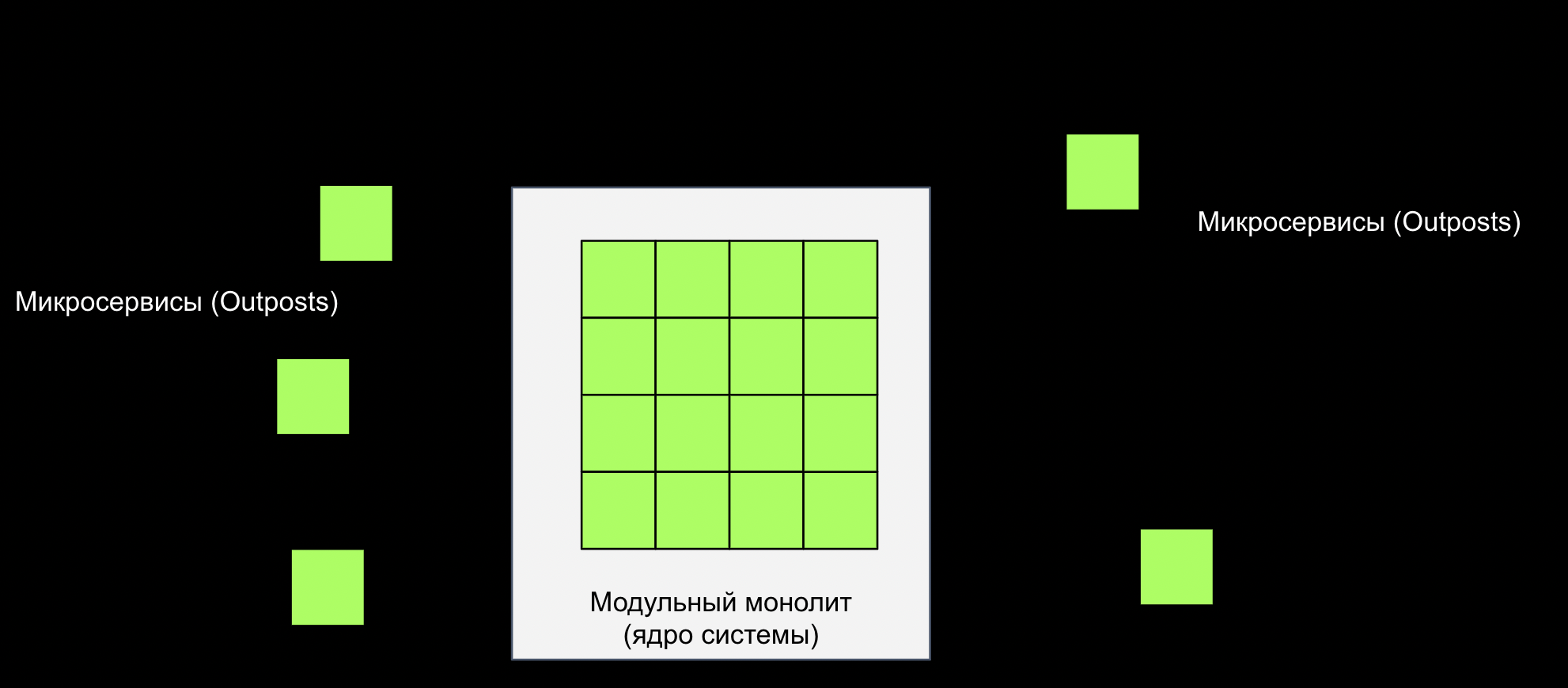
У нас есть монолит, в котором живет ядро системы. И могут быть микросервисы, которые мы выделяем тогда и только тогда, когда не получается его не выделить без ухудшения качества системы.
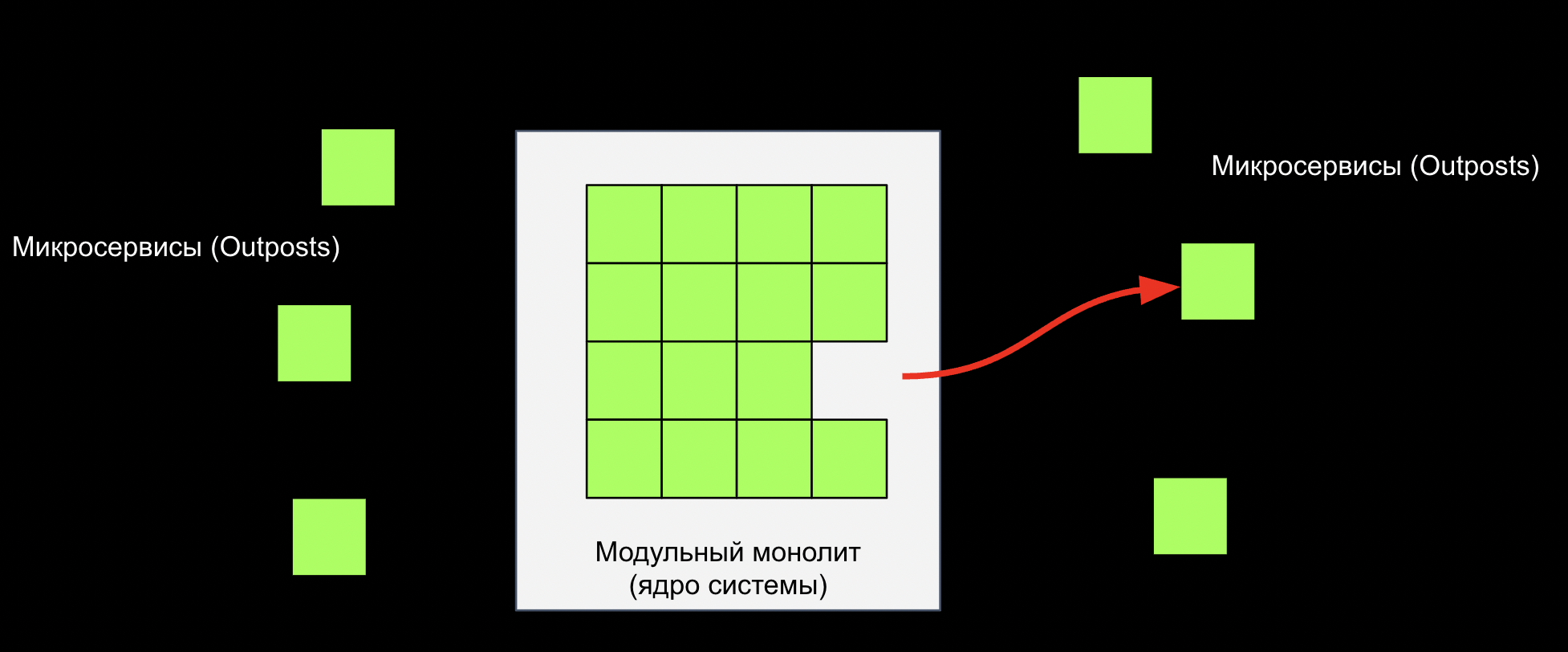
Есди какому-то фрагменту монолита становится тесно внутри, мы выносим его в микросервис. Модульная архитектура делает эту задачу легкой прогулкой: каждый квадратик внутри монолита — модуль, личинка микросервиса.
Глядя на эту картинку у многих может возникнуть комментарий: “Да у меня прямо сейчас такая система!”. Очень часто в момент перестройки изначально монолитная система выглядит так: есть основное приложение и есть выделенные микросервисы.
Ключевое различие тут в том, что это — не переходное состояние. Нет цели распилить монолит, выкинуть его и забыть про него. Напротив, при таком подходе команда старается максимально долго и продуктивно пользоваться теми плюсами, которые дает монолитная архитектура, избегая проблем микросервисной архитектуры. Для малых и средних проектов такая система будет гораздо удобнее и дешевле в доработке и эксплуатации, нежели полностью микросервисная.
Все ли это? Нет. Есть еще несколько вопросов, которые было бы интересно обсудить в контексте этой темы.
- Если все так плохо, почему всё равно все живут на микросервисах?
- Если зря выделили микросервис, можно ли засунуть его обратно?
- А что если делать сервисы, но не “микро”?
- Что делать с человеческим фактором? Никто не хочет работать с монолитом в 2026 году.
Каждый из этих вопросов может стать самостоятельной темой для дискуссии, но пожалуй оставим ее на следующий раз. Сейчас мы дошли до точки, где можно остановиться и повторить вывод, который сделали ранее.
Не делайте микросервисы только потому что “все так делают”. Любая идея, ставшая догмой, теряет свою магию. Используйте лучшие практики, но не принимайте на веру их “лучшесть” без критического осмысления. И тогда ваши системы будут отвечать на поставленные вызовы наиболее эффективным образом.